PDFにOCRをかけてテキスト化するのって、本当に便利ですよね。
紙の資料も検索可能になるし、勉強用に使うときにも情報整理しやすくなります。
私も日常的に使っていて、最近ではWondershareの「PDFelement」を重宝していました。
ある日、過去にまとめた勉強資料を一括でOCR処理しようと思い、PDFelementのバッチOCR機能を使って処理を実行しました。
バッチOCR機能とは, 多数のPDFファイルをOCR処理にかけることができる機能です。
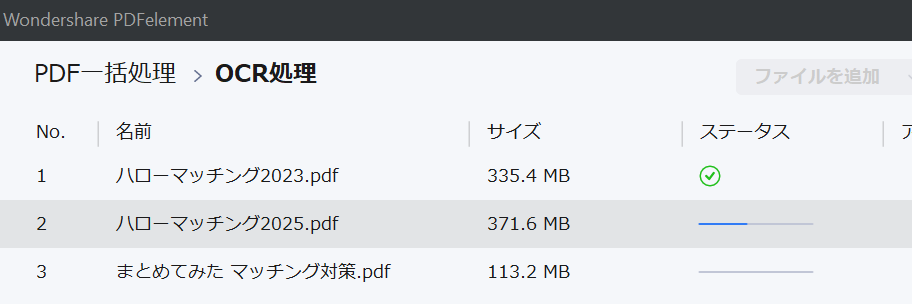
保存先はOneDrive上の同期フォルダ。
特に何も考えず、元PDFファイルを複数選び、処理スタート。
ところが処理の途中でアプリがフリーズ。しばらく待っても動かず、仕方なく再起動。
再度ファイルを確認してみると…
なんと、元のPDFが丸ごと消えていました。
名前を変えたファイルもない、ごみ箱にもなし。
頭が真っ白になりました。
まぁ他のソフトを使用しているときもこういうエラーが起こることも多々あったので, 落ち着いてまずはログを確認します。
ログは以下の場所に保存されています。
C:\Users\<ユーザー名>\AppData\Roaming\Wondershare\PDFelement\log
すぐにログを確認し, 相棒のChatGPT先生にログファイルを渡して解析をお願いしました。(ほんといつもありがとうな…)
ChatGPT先生によれば, 以下の回答がありました。
PDFelementはOCR処理中に一時ファイル(.tmp)を作成し、最終的に元ファイルと同じ名前で出力する動作をしている。
そして私の設定では「出力ファイルにサフィックスを付けない」ようにしていたため、元ファイルが上書きされるin-place processing(破壊的処理)が行われていた。
まぁ難しいことを言っていますが,
要するに、処理後のファイルが元のファイルと同じ名前だったせいで、作業途中に何かあると元ファイルまで巻き添えで消えてしまう、という危険な状態だったのです。
もっと優しくするならば,
元のファイルにそのまま上書きをしたため, エラーが発生して中断されると元のファイルごと消えてしまうというわけです。
さらに悪かったのは保存先がOneDriveだったこと。
クラッシュによって処理が中断され、一時ファイルも破損。
PDFを復元することもできず,
ローカルのごみ箱にも、「以前のバージョン」にも何も残っておらず、ほぼ詰んだ状態。
泣きそうになりながら, ダメ元でOneDriveのゴミ箱にアクセスしてみると…
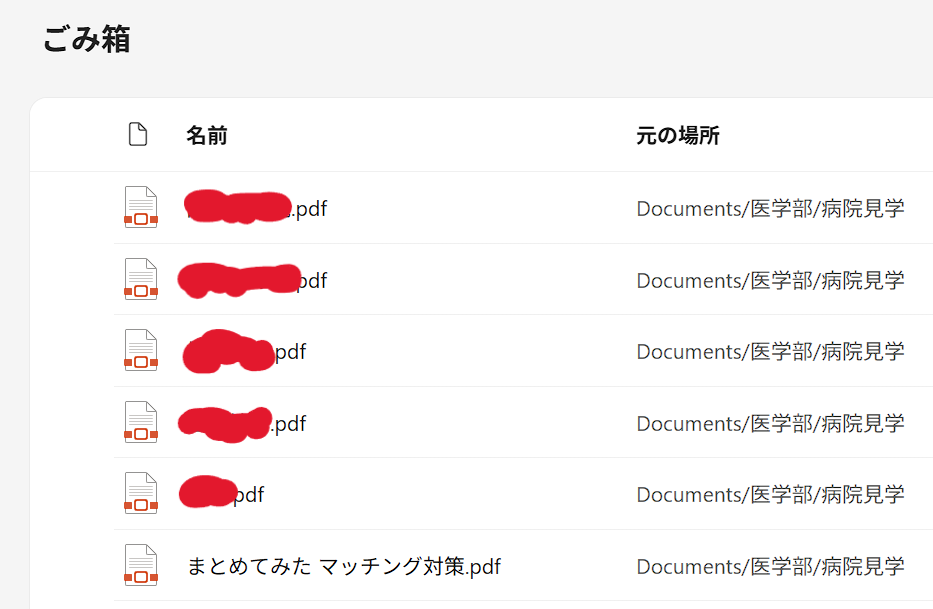
ありました(´;ω;`)
いやぁほんとに良かった。
この件から得た教訓
- OCR処理前には必ず元ファイルをローカルに複製
- 出力ファイル名に必ずサフィックス(例:_OCR)を設定
- OneDriveやDropboxなどの同期フォルダ上で作業しない
サフィックスは以下の場所から設定します。
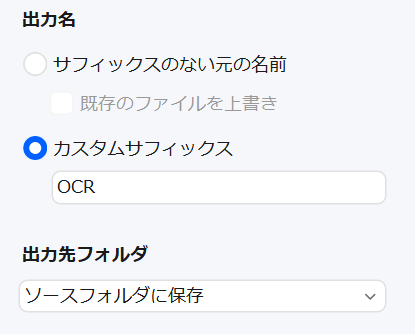
PDFelementのような便利なツールでも、こうした仕様に気づかないまま使っていると、データ消失のリスクが非常に高いです。
特に「in-place processing」, つまり, 元ファイルと同じ名前で出力するような処理では、処理が中断された時に元データを丸ごと失う可能性があります。
ちなみに、私はこの件についてWondershareのサポートにも連絡を取りました。
ログやクラッシュファイルなども送って状況を伝えましたが、現時点で明確な修復策は提示されていません(※2025年5月時点)。
今後改善されることを願っています。
あなたが同じ悲劇に遭わないために
以下の「事前チェックリスト」を作ってみました。
- 保存先はローカルフォルダか?(同期フォルダでないか)
- 元ファイルは複製済みか?
- 出力にサフィックスをつけているか?
- OCR処理中に異常終了した場合の復元手段を知っているか?
こうした事故は「自分は大丈夫」と思っているときに限って起こります。便利な機能ほど、裏には設計的な落とし穴が潜んでいる。
私のような悲劇を繰り返さないためにも、この記事が少しでも参考になれば幸いです。
それでは, 快適なデジタルライフを( ´ ▽ ` )ノ